NACLO 2022 - Problem MA Splitting Disagreement
Invitational round | 10 points | 54.32% | Problem statement | Official solution | Tags: Computational
M1:
Calculate the score for each algorithm applied to each sentence.
-
For the baseline, for all sentences, (the one at the end), (never adds extra word boundaries), where is the number of expected word boundaries. Therefore . These three sentences have 6, 4, 3 boundaries respectively, so scores are , , and respectively. This matches Alg A.
-
For Pavan's algorithm, we need to find the final consonants. Sentence 1:
, , so . This matches Alg C.
-
This leaves Arun's algorithm to be Alg B.
For Arun's algorithm applied to sentence 3, note that there's no need to actually do segmentation. The current score is 1.00, which means it matches exactly, with , . If the real segmentation has one extra boundary, then while doesn't change, so the score becomes .
Finally we are onto some real business. We want to translate the algorithm to an FST. There's really nothing linguistically significant about this.
Let's first understand the baseline algorithm. It wants to output a single 1 at the end, which looks like:
However, an FST cannot look ahead (by the time it outputs for the last character, it doesn't know what's coming next yet), so this machine here exploits nondeterminism to simultaneously output 0 and 1 for every character. Then, the last transition is forced to be the one that outputs 1 in order to arrive at the accepting state.
Here's Pavan's algorithm:
The first conditional is easy to implement, because it references the current character: just add a self-transition that outputs 1 on final consonants. Then, the remaining thing is the same as the baseline. This results in the FST shown in the solution.
Finally, Arun's algorithm is:
So the last is V part is already implemented as a state. The tricky part here is the next1 is IC and next2 is V part, because, again, we can't look into the future. We have to use nondeterminism for the input end, because there's no "end boundary character" for us to trigger the decision that "now we've reached the end". However, if we do have next characters, there's another way to do lookahead without nondeterminism: we can simply delay output until we've already seen the IC and V parts.
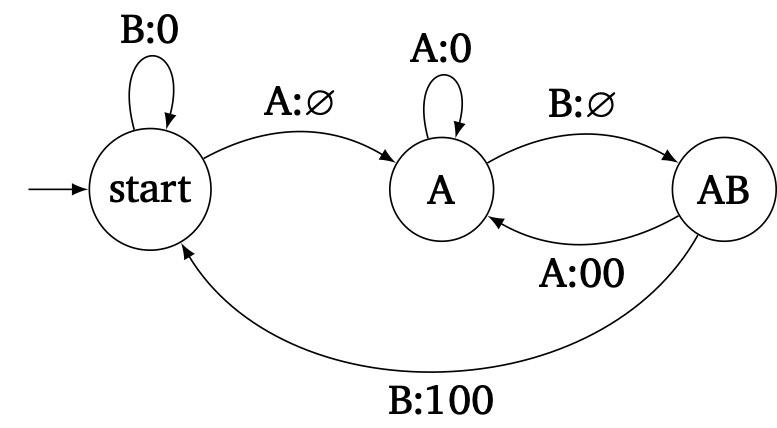
I illustrate the idea with the following simple algorithm: in a string of A's and B's, output 1 if the current character is A and the next two characters are B, otherwise output 0. This is technically a lookahead, but we can simply hold the output until we've seen the next two characters, and then decide what to output for all previous ones. That is:
- When we are not tracking anything, and we see a B, just output 0.
- When we see an A, don't output anything yet because we don't know if this should be a 1 or a 0. Move to state "A".
- When we are in state "A" and we see a B, move to state "AB" and still don't output anything yet. When we are in state "A" and we see an A, we know the previous A should be a 0, so output 0 and stay in state "A". Essentially, we make sure we are always withholding output for just the last A.
- When we are in state "AB" and we see a B, we know the previous A should be a 1, so output 100 for this whole "ABB" sequence and return to the start state. When we are in state "AB" and we see an A, we know the previous A should be a 0, so output 00 for the previous "AB" sequence and move to state "A", withholding output for this new A, which might be the start of another "ABB".
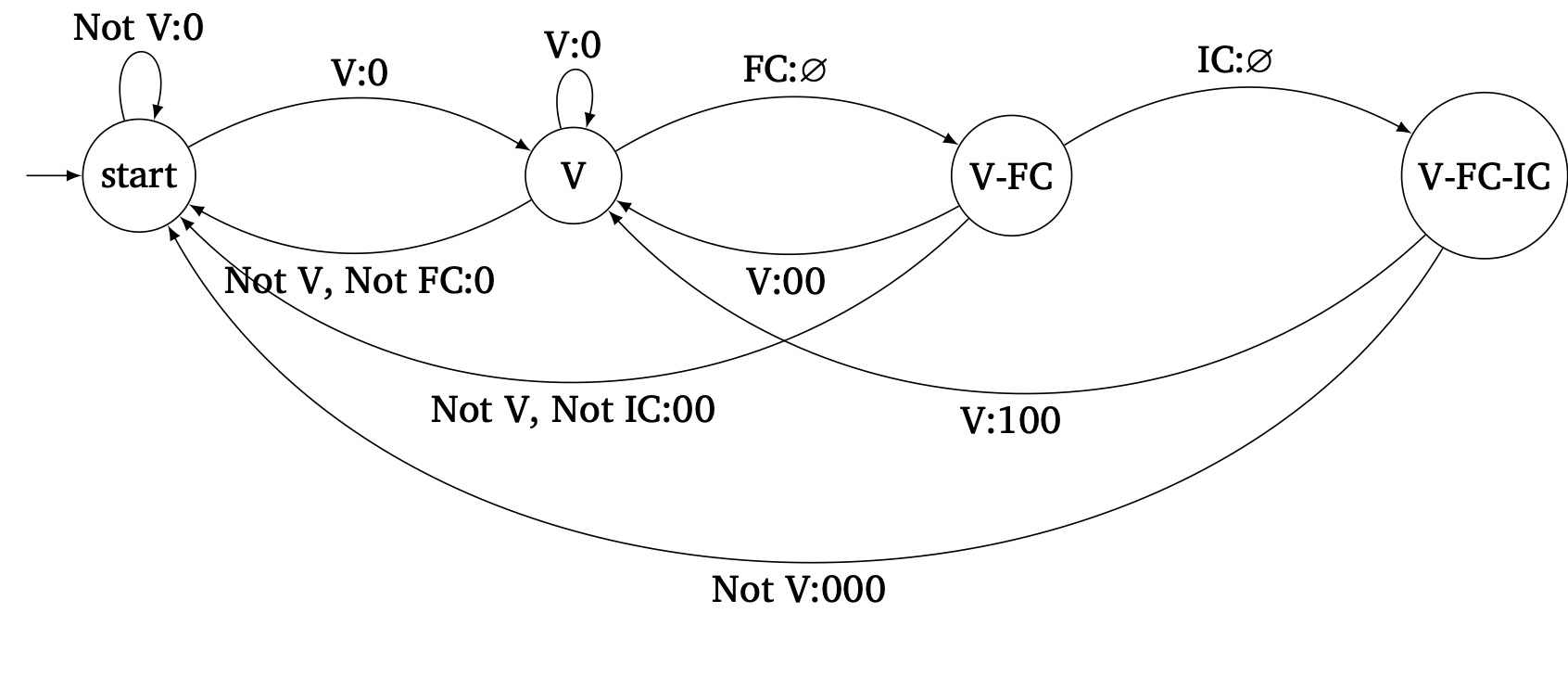
In the real algorithm, the idea is highly similar, except we need to track a prefix of length 3 instead of 2.
- If we see a V, we move to state "V" and output 0—no need to withhold here because the output is certain.
- If we are in state "V" and we see a FC, we move to state "V-FC" and withhold output, because this FC can either be 1 or 0. If we see anything else, we can't make progress so we keep outputting 0. If this new character is a V, we stay in state "V"; otherwise, we return to the start state.
- If we are in state "V-FC" and we see an IC, we move to state "V-FC-IC" and still withhold output. If we see anything else, this invalidates the "V-FC" sequence, so we output 00 for the FC and latest character. If this new character is a V, we move to state "V"; otherwise, we return to the start state.
- If we are in state "V-FC-IC" and we see a V, we know the previous "V-FC-IC-V" sequence should output 1, so we output 100 for FC, IC, and V respectively, and return to the "V" state. If we see anything else, this invalidates the "V-FC-IC" sequence, so we output 000 and return to the start state.
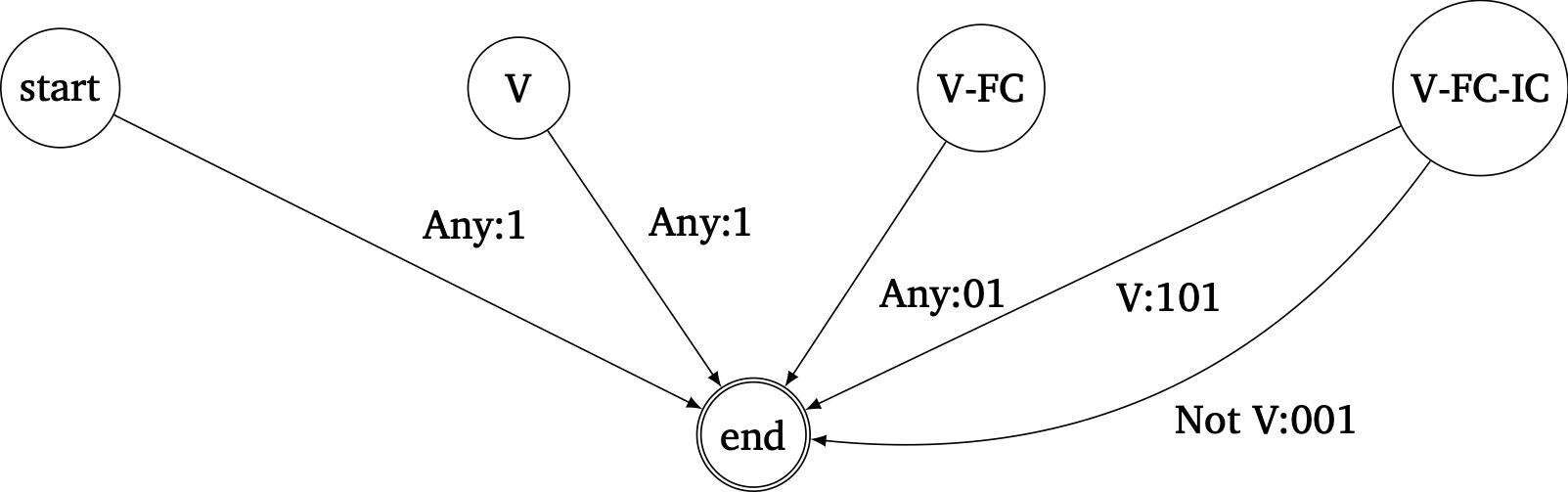
But this is assuming the input grows infinitely. If the input ends, then we can no longer withhold output; we must output whatever we have on hand. However, we run into the same problem of not having an "end boundary marker" that we can receive and trigger "cleanup". So we again have to resort to non-determinism.
We can enter the "end state" at any point. If we are in the start, V, V-FC state, we can just output 1, 1, 01 respectively since the early termination invalidates any sequence we're withholding, and the final character itself is a 1. If we are in the V-FC-IC state, however, if the final character happens to be a V, then we should actually output "10" for the FC-IC sequence instead of "00". Therefore the termination part looks like this (in addition to the previous FST):